

Видеокарта GeForce GTX 680: Nvidia подтвердила лидерство в области графичес

На этот раз конкурент в лице Nvidia не заставил ждать себя полгода, и уже в конце марта — начале апреля мы сначала официально услышали, а потом и получили возможность «пощупать» новую графическую архитектуру этой фирмы — Kepler. В настоящее время она представлена единственным графическим процессором GK104 и основанной на нем «видюхой» GeForce GTX 680.
При беглом взгляде на основные характеристики нового процессора от Nvidia (см. табл.) сразу замечаешь несколько необычных деталей. Во-первых, его обозначение: GK104. Раньше для наиболее производительных кристаллов эта фирма всегда использовала число, оканчивающееся нулем (например, GT200 или GF110, на которых в свое время были созданы GeForce GTX 280 и 580 соответственно), цифра же 4 в конце номера говорила, что перед нами процессор «верхне-среднего» уровня, но никак не «топ». Во-вторых, ширина шины памяти в 256 бит в полтора раза уже, чем у предыдущего лидера этой же фирмы, процессора GF110 (384 бит). Наконец, по числу транзисторов GK104 хоть и обошел GF110, но ненамного — 3,54 млрд против 3 млрд, что составляет 18%. Конкурент же увеличил этот показатель сразу на 63% (4,31 млрд в Tahiti против «всего» 2,64 млрд в Cayman). Обо всех этих странностях мы поговорим позже, а пока заметим, что, имея на четверть меньше транзисторов, чем у «заклятых друзей», новому процессору Nvidia будет весьма трудно вернуть фирме лидирующие позиции, которые она почти без перерыва занимает уже очень долгое время.
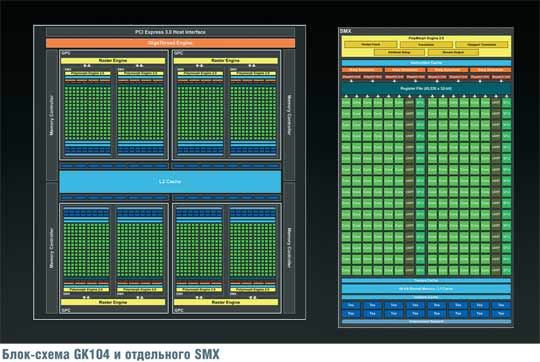
Новый графический процессор Nvidia (см. рис.), как и его предшественники, состоит из четырех крупных блоков — GPC (Graphics Processing Clusters, т. е. кластеров графической обработки), каждый из которых, по сути, является почти законченным процессором. Кроме них, на кристалле находятся кэш-память второго уровня, контроллеры памяти со связанными с ними блоками растровых операций (ROP), интерфейс шины PCI Express (на этот раз 3-й версии) и так называемый GigaThread Engine («гигапоточный движок»), являющийся своего рода командным центром всего графического процессора.

GPC впервые появились в процессоре GF100 (GeForce GTX 480), где их тоже было четыре. Как и прежде, основной частью GPC являются потоковые мультипроцессоры. В Kepler они носят обозначение SMX вместо ранее применявшегося SM (т.е. Streaming Multiprocessor). Смена обозначения указывает на существенные изменения, которым подверглись эти блоки. Заметим, что если раньше в GPC имелись четыре SM, то теперь лишь два SMX. Кроме них в GPC входят разделяемая память (64 Кбайт), играющая также роль кэша первого уровня; 16 блоков выборки и фильтрации текстур; регистровый файл, хранящий используемые мультипроцессорами данные (его емкость составляет 65,536 тыс. 32-разрядных слов); переработанный PolyMorph Engine («полиморфный движок»), получивший обозначение версии 2.0; кэш инструкций и четыре планировщика «варпов» с двумя диспетчерами каждый. Английский термин warp пришел из ткацкого производства и применительно к графическим процессорам Nvidia означает группу потоков, которые будут выполняться параллельно, как если бы они были единым целым. Здесь налицо аналогия с параллельно идущими нитями ткани, ведь «нить» по-английски — thread, а именно этим словом применительно к вычислительной технике в английском обозначают то, что на русский язык обычно переводится, как «поток».
Как видно из рисунка, каждый SMX включает в свой состав 192 вычислительных ядра (Nvidia использует для их обозначения термин CUDA cores или просто cores), выполняющих все основные арифметические и логические операции над данными. На каждые шесть таких ядер приходится по одному блоку специальных функций (SFU), который отвечает за выполнение таких сложных операций, как, например, вычисление синуса или квадратного корня, и чтение/запись из памяти (LD/ST, т. е. load/store). Никаких интересных подробностей относительно вычислительных возможностей нового процессора фирма не сообщает: по всей вероятности, принципиальных изменений в этом плане по сравнению с архитектурой Fermi нет. Налицо лишь трехкратный рост числа вычислительных ядер в одном процессоре (1536 против 512).
Очень важным изменением стал отказ от работы вычислительных блоков на удвоенной частоте процессора. Хотя этот подход, применявшийся Nvidia уже долгое время, обеспечивал более высокую производительность (теоретически — в два раза), он был сопряжен с приличным усложнением управляющей логики. Вероятно, последнее вкупе с улучшением техпроцесса, позволившим повысить количество вычислительных блоков без увеличения площади кристалла, и заставило Nvidia отказаться от такого подхода. Определенную роль наверняка сыграло и стремление снизить энергопотребление и тепловыделение (ниже частота — меньше энергопотери). Ведь еще два года назад компания заявляла, что улучшение энергоэффективности станет одним из главных направлений совершенствования ее графических процессоров. Как утверждает фирма, отказ от удвоенной частоты для вычислительных блоков привел к увеличению занимаемой площади (вероятно, привел бы, если бы не изменилась технология — ведь фактически речь идет о числе транзисторов, а не об их размерах как таковых) на 80%, однако сократил энергопотребление на 10% за счет упрощения схемы и еще на 50% за счет снижения частоты при сохранении аналогичной производительности.
Также одним чрезвычайно важным и неожиданным путем упрощения управляющей логики стал отказ от аппаратного отслеживания зависимостей по данным между различными потоками, который Nvidia проиллюстрировала на схеме в презентации архитектуры Kepler.
В архитектуре Fermi инструкции выбираются из кэша (Inst. Cache) и попадают в декодер (Decoder), откуда отправляются в очередь (Multi-port Post-decode Queue). Аппаратура непрерывно следит за тем, какие регистры уже используются и какие будут использоваться выполняемыми и находящимися в очереди командами (Multi-port Register Scoreboard), и выявляет зависимости между ними (Dependency Check): нельзя ведь начать выполнять (Issue) команду, исходные данные для которой еще не готовы. Во избежание существенной потери производительности, планировщик умеет переупорядочивать (Reorder) поток команд таким образом, чтобы не зависящие от других инструкции могли выполняться раньше, чем формально предшествующие им, но «завязанные» на еще не готовые данные. Этот механизм, хотя и существенно повышает эффективность работы процессора, весьма сложен. В центральных процессорах компьютеров, имеющих сложную и запутанную систему команд, альтернативы для него нет, а степень удачности реализации механизма переупорядочивания во многом определяет итоговую производительность ЦП (именно благодаря переупорядочиванию и некоторым другим «тонким» механизмам кристаллы от Intel при меньшей тактовой частоте показывают существенно более высокую производительность, чем конкуренты от AMD).
В графических процессорах, имеющих сравнительно простой набор команд, это не так. В архитектуре Kepler мы видим тот же кэш инструкций, команды из которого с помощью информации о планировании (Sched. Info) выбираются (Select) для декодирования и немедленного выполнения. Эта таинственная информация создается заранее, во время компиляции программы (шейдера), которая должна быть выполнена на графическом процессоре. Для обычных ЦП этот путь неприемлем, поскольку программы для них распространяются обычно в уже готовом к выполнению виде (в случае Windows — уже скомпилированные exe- и dll-файлы). Значит, они не могут быть подстроены под особенности конкретного процессора, но должны работать на любой предыдущей и, что важнее, будущей модели. Однако для графических процессоров программы поставляются в сыром виде. Например, компиляция используемых игрой шейдеров осуществляется во время загрузки игры, а то и в ее процессе. Поэтому компилятор для графического процессора может быть «заточен» (и на практике «затачивается») под конкретную его разновидность. Соответственно, он точно знает, сколько времени будет выполняться та или иная команда, насколько быстро результаты одной операции могут быть переданы для использования в другой и т. д. Именно этим и воспользовались инженеры Nvidia: компилятор, превращая исходный текст шейдера в машинный код, параллельно анализирует все взаимосвязи команд и создает информацию, позволяющую «железу» выбирать и исполнять команды в нужном порядке без применения сложных аппаратных блоков. Правда, подобный подход наверняка ухудшает производительность в некоторых случаях по сравнению с аппаратной реализацией, однако резкое упрощение управляющей логики позволяет — по крайней мере, в теории — повысить скорость ее работы (сами по себе вычислительные блоки и так быстрые) и увеличить число исполнительных блоков.
Контроллеров памяти у нового графического процессора всего четыре — вдвое меньше, чем было в предыдущих топовых кристаллах. Чтобы сохранить приемлемую пропускную способность, фирме пришлось повысить реальную частоту памяти до 1500 МГц (эффективная частота в 4 раза больше и составляет 6000 МГц), что на сегодняшний день является безусловным рекордом. Раньше подобными достижениями хвасталась AMD, но больше из-за того, что у Nvidia, традиционно использовавшей более широкую шину памяти, просто не было такой нужды.
Побочным следствием уменьшения числа контроллеров памяти стало и уменьшение количества привязанных к ним блоков растровых операций (ROP): если у GF100/ GF110 их было 48, то у GK104 — только 32. В результате, несмотря на рост частоты, максимальная скорость заполнения у новинки снизилась до 32,2 Гпикс/с против 37,1 у лидера предыдущего поколения. Правда, у конкурента в лице Radeon HD 7970 она еще ниже — 29,6 Гпикс/с.
Еще одно следствие сравнительной узости шины — установка на плату видеопамяти объемом лишь 2 Гбайт, в то время как и у конкурента, и у GeForce GTX 580 имеется 3 «гига». Правда, на умеренных разрешениях, включая все более популярное Full HD (1920 x 1080 точек), лишний гигабайт вряд ли сыграет роль, но производительность новых графических процессоров уже позволяет во многих случаях использовать и максимально возможное разрешение одного обычного монитора (2560 х 1600 точек). Хотя существуют и более «навороченные монстры», и комбинации из двух или более мониторов, а в этом случае «игропригодность» может определяться как раз объемом памяти.
Чрезвычайно важным и в плане производительности, и в плане энергопотребления является внедрение новой технологии, получившей название GPU Boost. Оно не зря созвучно с Turbo Boost, как Intel назвал свою технологию «саморазгона» центральных процессоров. В первом приближении сущность обоих этих «бустов» одинакова. Имеется некоторая базовая частота, на которой процессор гарантированно работоспособен (для GK104 она равна 1006 МГц). Однако, если имеется запас по потребляемой мощности и нет перегрева, эта частота может быть превышена, если того требует исполняемое приложение. Благодаря этому, с одной стороны, достигается экономия энергии (нет полной загрузки — процессор работает не на максимальной частоте), а с другой — появляется возможность использовать резервы для повышения производительности. Nvidia даже ввела понятие средней частоты при разгоне («турбочастота»), которая для GK104 равна 1058 МГц: это значение является типичным при выполнении реальных приложений. Понятно, что при появлении очень «тяжелой» задачи (как правило, такими являются специализированные тесты) частота снизится, поскольку в противном случае процессору грозит перегрев, а если работа не слишком сложная — может и превысить эту отметку.
Приятным новшеством является адаптивная вертикальная синхронизация (Adaptive VSync). Во всех предыдущих решениях, что Nvidia, что ее конкурента, для вертикальной синхронизации были возможны лишь два значения: «включена» или «выключена». Если синхронизация выключена, отображение каждого кадра начинается в тот момент, когда он будет полностью сформирован. Учитывая, что частота вертикальной развертки монитора постоянна (обычно 60 или 75 Гц), а время формирования кадра переменно и зависит от многих факторов, довольно часто происходит так называемый разрыв кадра: смена кадров происходит во время отображения, в результате верхняя половина соответствует старому изображению, а нижняя — новому. Если же синхронизация включена, вывод нового кадра начинается лишь после того, как монитор полностью отобразил предыдущий. Это полностью исключает возможность разрыва кадра, однако привязывает скорость рендеринга к частоте развертки. Если подготавливать новые кадры с нужной скоростью не получается, реальная их частота падает в два, три и более раз по сравнению с частотой развертки. Например, если некоторая сцена технически может воспроизводиться со скоростью 55 кадр./с, а монитор имеет частоту вертикальной развертки 60 Гц, то при включенной вертикальной синхронизации реальная частота кадров составит всего лишь 30 Гц. Поэтому игроки обычно отключают вертикальную синхронизацию и мирятся с возникающими время от времени разрывами кадров — лишь бы общая плавность игры не страдала.
Адаптивная синхронизация решает обе проблемы очень простым способом. Если новые кадры появляются с необходимой скоростью, они будут выводиться лишь после полного отображения предыдущих, то есть при включенной вертикальной синхронизации. Однако если производительность графического движка просядет (например, попадется особо сложная сцена), вертикальная синхронизация будет отключена, результатом чего станет появление время от времени разорванных кадров, но плавность игры сохранится.
Еще одна «добавка» — появление блока аппаратного кодирования видеоданных. Декодеры в «видюхах», даже очень слабых, существуют уже давно; именно с их помощью «тяжелые» фильмы в Full HD можно смотреть даже на «слабых» компьютерах, где центральный процессор просто не справится с декодированием данных в реальном времени. Однако обратный процесс долгое время осуществлялся исключительно программно. Теоретически его можно было сильно ускорить путем переноса основной тяжести кодирования с центрального процессора на графический. Однако на практике в полном объеме этого так и не произошло. Во-первых, написание программ для ГП требует специфических знаний и навыков, поэтому под силу далеко не всем. Во-вторых, ощутимое ускорение могли дать лишь мощные графические процессоры — дорогие и «горячие», а программное кодирование на решениях среднего и тем более нижнего уровня не давало фантастического прироста производительности по сравнению с более-менее приличными центральными процессорами. Теперь же кодирование в формат H.264 будет осуществляться аппаратно, причем, по утверждению Nvidia, в 4–8 раз быстрее, чем нужно для отображения в реальном времени (т. е. часовой фильм в разрешении Full HD может быть закодирован за 8-15 мин.).
Среди прочего отметим появление новых методов полноэкранного сглаживания изображений — FXAA и TXAA (правда, к новой архитектуре они отношения не имеют и могут применяться, во всяком случае технически, на предыдущих «видюхах» и даже на «железе» конкурента — лишь бы имелась программная реализация соответствующих алгоритмов). Точнее говоря, FXAA уже некоторое время применялся (впервые — в игре Age of Conan, вышедшей в 2011 г.), но пока широкого распространения получить не успел. В новых драйверах Nvidia (версия 300 и последующие) его можно включить принудительно. Он обеспечивает несколько худшее качество, чем MSAA, зато намного меньше нагружает «железо», что особенно важно при высоких разрешениях.
Что касается действительно нового метода TXAA, то здесь упор делается прежде всего на качество при сохранении высокой скорости. Как утверждает фирма, TXAA 1 имеет несколько более высокое качество, чем 8x MSAA, но работает со скоростью 2x MSAA. TXAA 2 создает картинку еще лучше, однако требует вычислительных затрат на уровне 4x MSAA.
Теперь самое время перейти к практике. На тестирование к нам поступил эталонный образец GTX 680 производства самой Nvidia. Эта плата имеет несколько меньшую длину, чем привычные «видюхи» верхнего ценового сегмента, и получает энергию через два шестиконтактных коннектора, а не через шести- и восьмиконтактные, что напрямую связано с более низким энергопотреблением. Имеются четыре видеовыхода — два DVI и по одному HDMI и DisplayPort. По субъективным ощущениям, система охлаждения шумит чуть меньше, чем у GeForce GTX 580 и нынешних «радеонов», но это тоже можно списать на меньшее энергопотребление. Нагретый воздух, проходя под кожухом, главным образом выбрасывается наружу из корпуса компьютера.
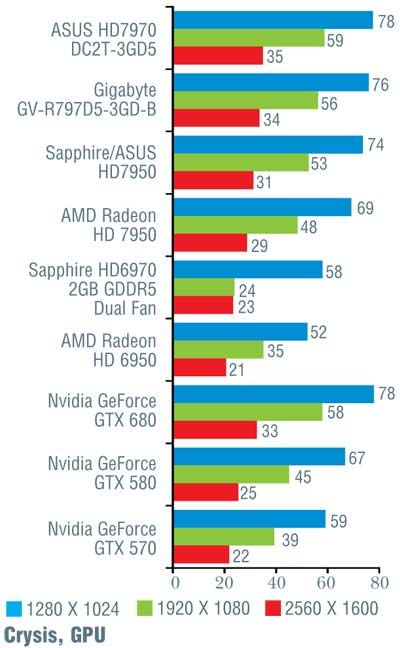
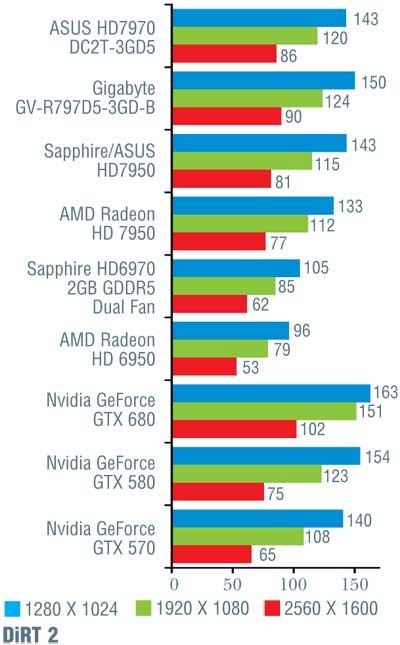
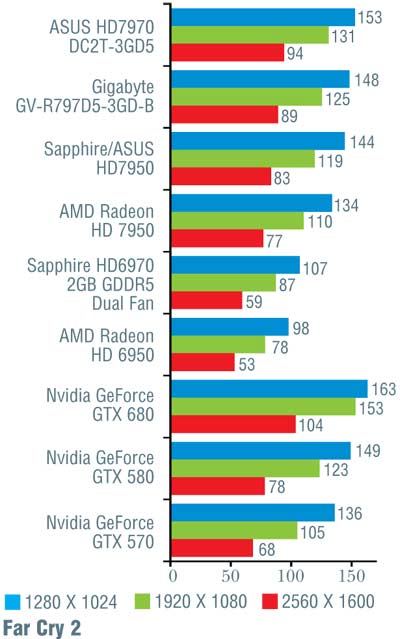
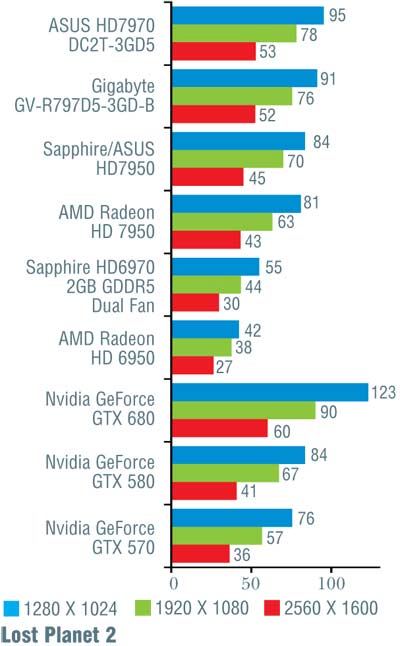
Тестирование проводилось на материнской плате Intel DP67BG с процессором Intel Core i7-2600K, 8 Гбайт ОЗУ (4 модуля DDR3 Kingston с эффективной частотой 1600 МГц и таймингами 9-9-9-27) и жестким диском Western Digital WD1002FAEX. Применялись драйверы версии 301.10. Тестовые прогоны выполнялись на максимальных настройках качества, за исключением полноэкранного сглаживания, ограниченного величиной 4х. Заметим, что на этот раз мы гоняли лишь новинку от Nvidia, а все остальные результаты взяты из проведенных ранее тестов видеоплат AMD Radeon HD 7970 и 7950. Наш тестовый набор пополнился двумя играми: Crysis 2 и DiRT 3. Однако, поскольку это первое их использование, а самих конкурирующих «видюх» в нашем распоряжении уже не было, полученные на них результаты указаны только для GeForce GTX 680 и в общем зачете не используются. Результаты тестирования представлены в таблице.
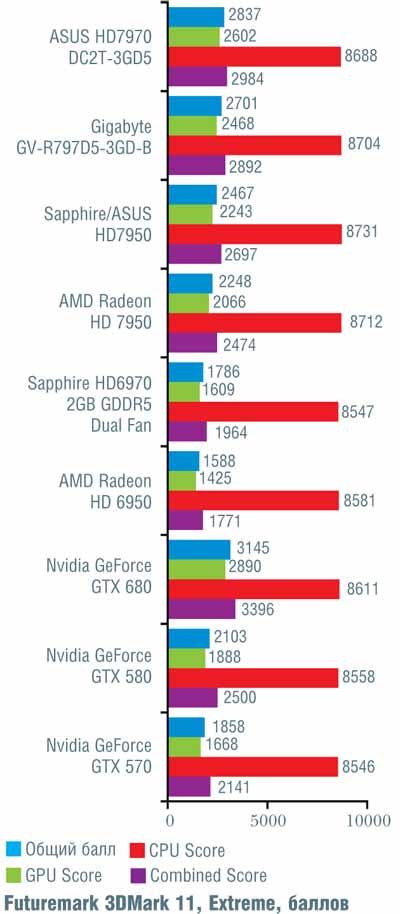
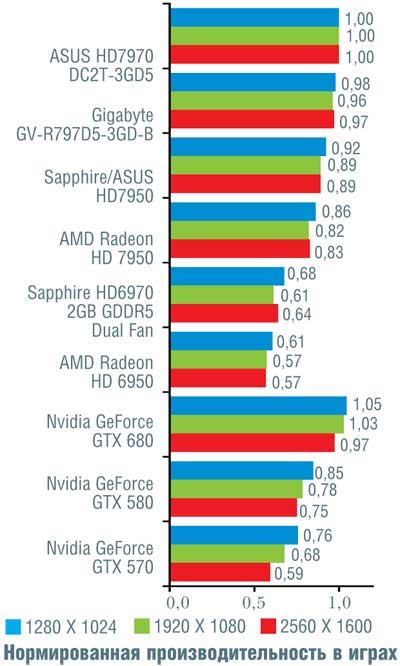
Если сразу посмотреть на итоговые результаты, то окажется, что на малых и умеренных разрешениях (1280 x 1024 и 1920 х 1080 точек) «Кеплер» обогнал «Таити» в среднем на 7%, и лишь на максимальном разрешении 2560 х 1600 точек, где AMD традиционно была сильнее, их результаты совпали. Вспомнив, что у конкурента намного больше транзисторов, приходится признать, что Nvidia показала просто блестящий результат, причем отнюдь не при помощи «грубой физической силы» (тех самых транзисторов).
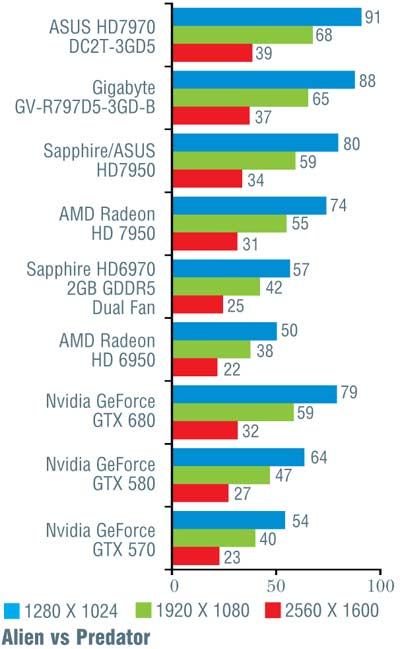
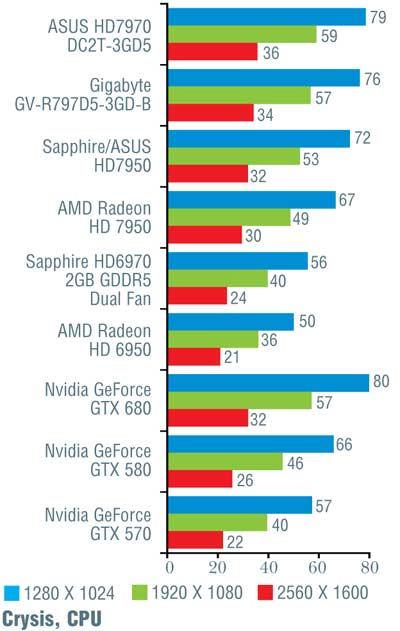
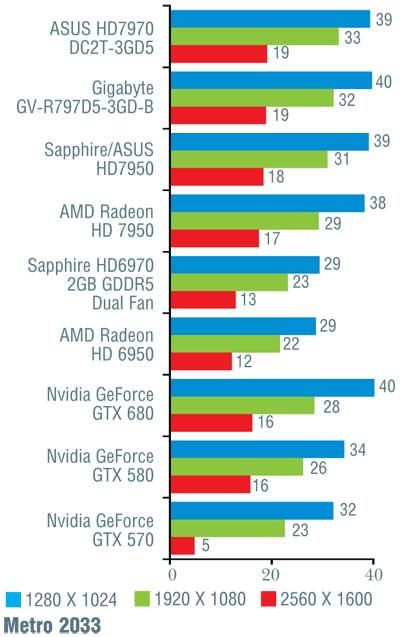
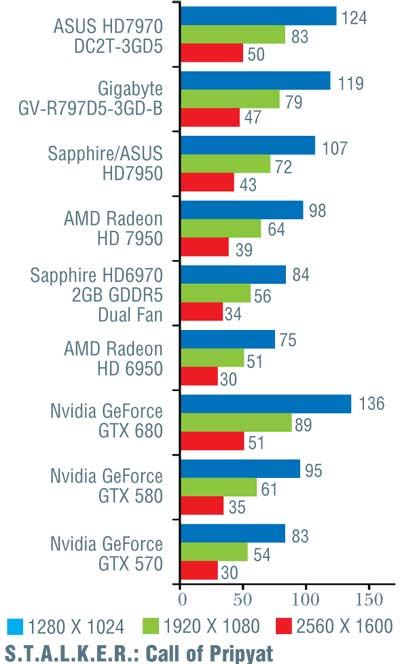
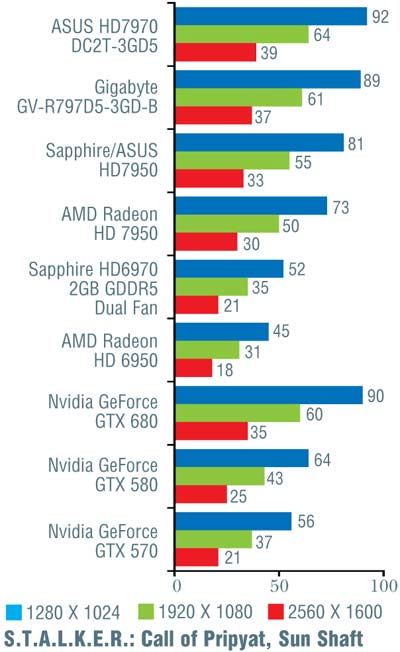
Конечно, при более тщательном рассмотрении все оказывается не так гладко. В игре Alien vs Predator новинка от Nvidia уступила решению от AMD, причем чем выше разрешение, тем больше отставание (от 10 до 16%). Хуже себя показала GeForce GTX 680 и в Metro 2033 (за исключением минимального разрешения 1280 x 1024 точки). В S.T.A.L.K.E.R.: Call of Pripyat в трех более простых тестах «невидия» лидировала, обгоняя конкурента на 7–12%, а вот на последнем, «тяжелом» режиме слегка уступила; впрочем, здесь разница не превосходила 5%. В Crysis, чуть-чуть превосходя соперника на низких и средних разрешениях, GeForce GTX 680 самую малость уступила при разрешении 2560 х 1600 точек. В остальных случаях превосходство «джифорса» было бесспорно и временами доходило до 26%, хотя обычно находилось в более скромных пределах.
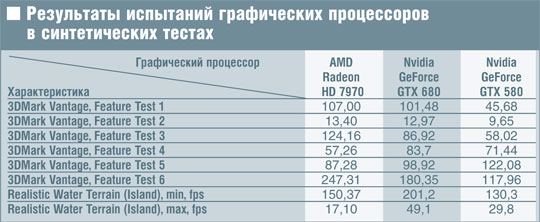
Теперь обратимся к «синтетике» (см. табл.). Первый feature test из пакета 3DMark Vantage заполняет прямоугольник значениями, выбранными из небольшой текстуры. Предыдущие процессоры Nvidia с разгромным счетом проигрывали на этой задаче «радеонам», поскольку скорость текстурных выборок у AMD была существенно выше. Калифорнийцам не удалось одержать победу и сейчас, однако разница существенно уменьшилась. Правда, если исходить лишь из скорости выборки текстур, победа должна достаться GeForce GTX 680. Вероятно, полностью раскрыть свой потенциал «кеплеру» помешала пропускная способность памяти, которая намного меньше, чем у конкурента. Тем не менее можно считать, что один из главнейших недостатков всех предыдущих решений Nvidia в целом устранен.
Второй тест определяет скорость заполнения и упирается как в этот показатель, так и в пропускную способность памяти. Раньше Nvidia ощутимо, хотя и не в разы, отставала от конкурента, сейчас же разница почти полностью сглажена, хотя Radeon HD 7970 чуть-чуть все же опережает «кеплера».
Третий тест, Parallax Occlusion Mapping, использует большое число текстурных выборок, динамические ветвления и сложные вычисления, очень сильно нагружая текстурные и вычислительные блоки процессора. Сравнительно невысокий результат новичка, сократившего разрыв, но все еще прилично отстающего от конкурента, может быть объяснен, среди прочего, упрощениями в вычислительных блоках, из-за чего они неспособны работать в полную силу на «неприятных» для них задачах.
Два следующих теста (4 и 5) моделируют физические расчеты на графическом процессоре. И в прежние времена решения от Nvidia оказывались лучше, чем конкуренты, так что неудивительно, что эта тенденция сохранилась. Однако если в первом из этих испытаний новый графический процессор показал несколько лучшие результаты, чем его предшественник, то во втором все обстоит в точности наоборот. Столь прискорбный результат (хотя по-прежнему лучше, чем у AMD) объясняется, по всей вероятности, меньшим (в 1,5 раза) числом блоков ROP и снижением скорости заполнения по сравнению с GeForce GTX 580.
Последний, шестой тест из 3DMark Vantage зависит почти исключительно от «математических способностей» графического процессора. AMD всегда демонстрировала наилучшие результаты именно на таких задачах, так что неудивительно, что Radeon HD 7970 сохранил свои лидирующие позиции. Вместе с тем заметим, что Nvidia резко сократила разрыв, процентов на 70 обойдя на «кеплере» свою предыдущую архитектуру. Вместе с тем до теоретического максимума этот результат явно не дотягивает: вероятно, здесь сказывается упрощение управляющей логики SMX, которое не смог скомпенсировать компилятор.
Наконец, тест Realistic Water Terrain позволяет проверить способности графического процессора в области тесселяции, хотя его результаты зависят не только от них. В отличие от аналогичных программ из Microsoft SDK, созданных фирмой AMD и поэтому просто не создающих значительной нагрузки на тесселяторы, этот тест является по-настоящему тяжелым. Что ж, если на минимальном уровне тесселяции топовое решение от AMD обошло теперь уже предыдущего лидера от Nvidia, то GeForce GTX 680 вернул все на свои места. А уж о максимальной тесселяции и говорить не приходится: хотя Radeon HD 7970 в этом плане много лучше своих предшественников, ему по-прежнему далеко даже до GeForce GTX 580.
Пора подводить итоги. Как мы убедились, Nvidia выпустила очень мощный процессор, по производительности несколько опережающий мощнейшее решение конкурента и, что крайне важно, при ощутимо меньшем числе транзисторов и более скромном энергопотреблении. Безусловно, Tahiti в целом является выдающимся достижением AMD и имеет резервы по ускорению (по всей вероятности, его можно разогнать на сотню мегагерцев, обеспечив соответствующее охлаждение), однако с точки зрения технического совершенства Nvidia подтвердила свое лидерство. И вот тут уместно вспомнить, с чего мы начинали эту статью. Мало того, что новый топовый процессор Nvidia лишь ненамного превосходит по числу транзисторов своего предка, так еще имеет урезанную наполовину шину памяти и странное обозначение — GK104 вместо ожидаемого GK100. Все это наводит на мысль, что Nvidia просто попридержала выпуск настоящего лидера нового поколения, выбросив на рынок более простой кристалл, прямым предком которого является скорее GF114 (видеоплата GeForce GTX 560), а не GF110. Тому найдется несколько причин. Одна из них может заключаться в том, что фирма изрядно намучилась с налаживанием выпуска GF100 по новой на тот момент 40-нм технологии. Из-за этого первые «видюхи» на его основе (GeForce GTX 480) имели лишь 15 активных GPC вместо 16 — выход годных кристаллов был слишком мал. Снова отставать от конкурента на полгода, а то и больше, в Nvidia просто не захотели. А во-вторых, получив доступ к первым серийным Radeon HD 7970, специалисты Nvidia смогли воочию убедиться, что GK104 способен конкурировать с новейшим и мощнейшим решением конкурента на равных и даже несколько превзойти его. Если эти мысли верны, то через некоторое время мы увидим какой-нибудь однопроцессорный GeForce GTX 690 (или GeForce GTX 780 — смена старшей цифры обозначения необязательно означает коренные изменения в технологии или архитектуре), наголову разбивающий конкурента, но при этом имеющий внутри где-нибудь около 5 млрд транзисторов. Так или иначе Nvidia смогла подтвердить свое лидерство в области высокопроизводительных графических решений, с чем мы ее и поздравляем.

Источник: Hard'n'Soft
Автор: Иван Савватеев





Комментарии читателей Оставить комментарий